 Open Policy Agent - Give it a try!
Open Policy Agent - Give it a try!
Introduction
Approximatively 3 years ago, I discovered the existence of the Open Policy Agent component.
At this time, I had the feeling this could be very interesting, and I suggested to my manager we could have a look on it (poke Christophe, maybe you remember that?).
But, as I was working on other topics, no real use cases were identified and lack of time, we did not.
I regret that… but, you know, I was not able to convince them, my bad. I’ll do better next time.
📅 In March 2018, the Cloud Native Computing Foundation - CNCF accepted OPA in the CNCF Sandbox.
📅 In April 2019, OPA move from Sandbox to incubation.
📅 In February 2021, OPA is now CNCF Graduated, giving to this tool another dimension, a certain proof of interest in the cloud native world.
… to make is short: this tool is something to be known and more than promising IMHO!
In addition to that, recently during my freelance activity, I came to know the big company (and my customer) I was working for is planning to use OPA in the context of their private cloud authorization mechanisms.
For all these reasons, I decided to have a deeper look onto OPA.
Please note this post will NOT be exhaustive.
It represents only a first approach and considerations.
It will probably be completed by other posts to come later (maybe in months😄). Because I’m pretty sure I will discover new features and options 🎉.
Open Policy Agent (OPA for short)
Even if the documentation website is pretty well written, let me give you some definitions with my own words (sometimes, several explanations of the same concept could help to better understand it … and let me be sure I understood 😄).
In software world, policies are often applied, to be able to take a decision.
These policies could be written with code instructions, as it could be represented by a succession of if, then and else, in its most basic form.
This is the case, for instance, for authorization checks.
Example
If user
arnadugais requesting publish ablog postand the length of it is more than 100 characters, the decision istrue. Else the decision isfalseto avoid publish by mistake of draft post with less than 100 characters.
The problem is this policy is often hardcoded into the application, avoiding easy change (ie recompilation and redeployment, possible service interruption, etc.) or re-usage.
OPA will help you to externalize these decision process and brings multiple advantages:
- Versioning: policies are text file (in specific language, REGO), so easy to version thanks to git for instance
- Sharing: the same policy file would be able to be used in multiple applications and usages as it applies to a business rule
- Decoupling: updating a policy is NOT a compilation issue anymore. Policies have their own and independent lifecycle
- Quicker activation: as it is a data source, current binary will be able to apply it very quickly, avoiding long deployment process (NO GO LIVE ON FRIDAY!). It can be appreciable in emergency situation, to revoke some rights for instance.
In fact, you will basically totally delegate the decision making process to a dedicated engine.
Note
I went through the Styra Academy - OPA Policy Authoring course to go deeper in my tests. It is quite well designed and explained. Recommended!
OPA architecture
Let’s quickly have a look on the way OPA could be integrated to your applications.
The documentation mentioned several possible integrations:
- Sidecar/Host level
- Libraries / WebAssembly
Sidecar
If you are working in Kubernetes environment 🐳, you can have an application POD that includes your application in one container, and OPA in another container.
The diagram would like this (I know, some shortcuts are done):
In this architecture, the PODS are autonomous, and embed everything you need: the application and the way to evaluate the policies. If the application container is down, the whole pod will be considered as dead (OPA engine alone is not interesting). Same case if the OPA container is down.
This second option supposes to maintain a dedicated deployment file. It can be interesting if your application is compounded of several modules and mutualized the OPA engine. However, it creates a dependencies between modules, in terms of OPA engine version (all using the same).
NOTE
As quickly suggested on diagrams, policies SHOULD be externalized from the container. This is required to keep the engine as clean as possible, and jusst consumes policies managed centrally.
In Kubernetes environment, you can achieve that thanks to Persistent Volume Claims (or PVC). In Docker world, by using volumes.
Library / WebAssembly
OPA is developed in Go Language (I promise, one day, I’ll try some things with it). As such, if your application is developped in Go language, you can import the OPA library and then, use the OPA API to interact with the engine.

As of now, I’ve seen not a lot project developed in Go in companies I worked for (except the one with Private cloud, that developed as well it own Terraform Provider … in Go)
So, this Go Lib solution is maybe interesting, but NOT suitable for a lot of projects.
It seems there are some other languages (probably by WebAssembly wrapping?) libraries.
However, the sidecar implementation seems more interesting, to continue in the decoupling way and to allow the engine to have its own deployment lifecycle (and updates, without impacting your application itself)!
Recommendations
STYRA, the company behind OPA, strongly recommends to use a sidecar deployment.
It could be shared on the same server as your application (deployed on a secondary port), in a dedicated POD, or sharing a POD with the application in Kubernetes world.

Of course, this means the OPA engine will be deployed multiple times, but not the policies themselves.
But, having the engine close to the application purpose is performance: OPA engine is small and stores and keeps all the policies only in memory. This presents a very low latency overhead!
Let’s implement an example
I won’t talk about the REGO language itself in this post: it is a complete language and, again, the Styra Academy - OPA Policy Authoring online course is pretty good.
To illustrate and show an example, I’ll consider a classical use case: API authorization, related to a weak and basic asymmetric keys service.
This API should allow to manage keys (CRUD) by username. Of course, not everyone will be allowed to do all the operations: this is were OPA comes to the scene.
API description
The API should offer these features:
POST /<username>/keys: Generate a new keypair for a user. Can be done only by<username>.GET /<username>/keys/public: Get the public key of a user. Any authenticate user can get it.GET /<username>/keys/private: Get the private key of a user. Only<username>can do it.PUT /<username>/keys: Revoke and regenerate a keypair for a user. Can be done only by<username>or a key managerDELETE /<username>/keys: Delete a keypair of a user, without generating another pair. Can be called by<username>or a key managerGET /healthcheck: a basic service healthcheck. Can be called by anyone, authenticated or not.
As a consequence, we can see 3 kinds of caller:
- Unauthenticated
- Authenticated and simple user: role named
user - Authenticated and key admin: role named
keymanager
Data helpers for evaluation
To evaluate a decision, OPA is taking 2 kind of inputs: inputand data, where:
inputdescribes the context ie everything that could be helpful to taken the decision: username of the caller, token, API endpoint called, etc…datacontains data useful for evaluation and to avoid hard coded. It can be, for instance, the list of role name considered askeymanager, a servers list, some authorized AMI list, etc.
These 2 inputs can be json or yaml format.
In our basic example, no external data are required to evaluate the decision, only the input.
Input format
The context needs to be described and committed between the API service and the decision (OPA) service. This means OPA obvisouly needs to know what will be the attributes to be received in order to evaluate (of course).
Here is an input example:
{
"input": {
"token": {
"username": "<username>",
"roles": [ "<role>" ]
},
"request": {
"path": "/path1/path2/path3",
"method": "GET"
}
},
"scenario" : {
"description" : "A nice description",
"expectedResult" : true
}
}
The role could user or keyadmin or both. Information is managed on authentication system.
The .rego file
The .rego file I wrote can be found here.
Here is an extract of it: the part that check the GET /<username>/keys/private call:
default allow = false
# Prepare the path
pathExploded := split(input.request.path,"/")
# Determine is the caller is the owner
is_owner {
input.token.username == pathExploded[1]
}
# Allow only owner to get its own private key
allow {
is_owner
{pathExploded[2], pathExploded[3]} == {"keys","private"}
input.request.method == "GET"
}
- First, we define a default value to the variable
allow, the one that will be interesting for us - The called
pathis then split, for easier use - The variable
is_ownerintents to betruewhen the caller (identified into theinput) is the same as the<username>of the path - Finally, we evaluate, for a
GETon<username>/keys/private, if the caller is legitimate to request that.
If everything succeeded, the allow variable will be then true. Otherwise, it will be false.
The input test files
I prepared some json file to be used as input. The archive file acn be found here
| Scenarios |
|---|
GET /healthcheck by a not authenticated user |
GET /arnaduga/keys/private by user1 |
GET /arnaduga/keys/private by arnaduga |
GET /arnaduga/keys/public by a user |
POST /arnaduga/keys by a user |
POST /arnaduga/keys by arnaduga |
DELETE /arnaduga/keys by a user |
DELETE /arnaduga/keys by arnaduga |
DELETE /arnaduga/keys by a key manager |
Additionally, in order to make it easier, I prepared a Postman Collection.
“(Ladies) Gentlemen … Start your engine!” 🏆
Pffui… 😝 Now, you have everything needed to TEST! … except the OPA engine itself.
To start an OPA server, for tests, I recommend to use a docker image.
So, first, be sure you downloaded the here file.
Then, in a command line shell, enter:
$ docker run -it --rm -p 8181:8181 -v $PWD:/pol openpolicyagent/opa run --server /pol/package.rego
Unable to find image 'openpolicyagent/opa:latest' locally
latest: Pulling from openpolicyagent/opa
ec52731e9273: Pull complete
8907fc4ab049: Pull complete
a1f1879bb7de: Pull complete
b7fafd3363cd: Pull complete
Digest: sha256:e048636291c58e11308ace8974d6b874aebd8908456ea7ed73fbefd8719bfa01
Status: Downloaded newer image for openpolicyagent/opa:latest
{"addrs":[":8181"],"diagnostic-addrs":[],"level":"info","msg":"Initializing server.","time":"2021-10-04T18:53:24Z"}
This command will:
- Download the latest version of the
openpolicyagent/opaDocker image (from Docker hub) if you don’t already have it locally - Launch the image with:
- a volume mounted on the current folder mapped to
/pol, to be able to read the.regofile - a port forwarding to expose the service (port
8181) - by starting the
opaengine with the appropriateregofile for policies - … that will be removed (the container, not the image) after run (option
--rm)
- a volume mounted on the current folder mapped to
Time to test!
Command line style 🤓
In another CLI window (the first is used to run the server … please try to follow!)
$ curl -XPOST http://localhost:8181/v1/data/arnaduga/api/authz/allow -d @GET-hc.json -H "Content-type: application/json"
{"result":true}
$ curl -XPOST http://localhost:8181/v1/data/arnaduga/api/authz/allow -d @DELETE-illegitimate.json -H "Content-type: application/json"
{"result":false}
$ # and so on with the other *.json files!
The first call, to evaluate if someone can GET /healthecheck even if not authenticated, returns true.
The second call, to evaluate if a user can create a keypair for someone else return false.
Pretty nice, hmm?
Postman style 📭
In Postman, first import the collection (sorry, I won’t explain here… this be be another post, later).
Then, in the imported collection, select the request you want to test.
… and hit the Send button.
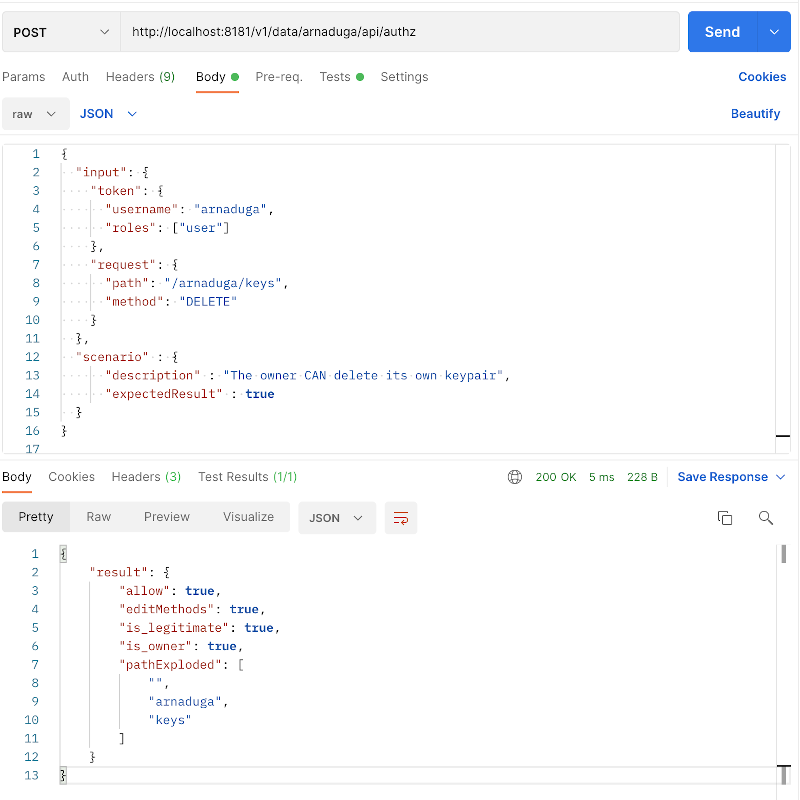
… and voilà!

Results
As your expert eyes 👀 may have notice, the curl command and the Postman URL are not the same. Believe me or not, it was done on purpose 😄!
- The
curlcommand targets specifically theallowvariable, declared and used inside theregopolicy:/arnaduga/api/authz/allow - The POSTMAN command targets the policy itself, and then, the response is the whole policies variables, including the
allowone.
Other interesting features
Bundles
Amongst the OPA’s feature, it seems there is the bundles way of working.
From what I qquickly read, it will allow the OPA engine to get new policy file on a regular basis from a policy repository.
This is really promising, as it will allow to very quickly deploy a new policy version in case of compromission or bugged policy!
I did not test it yet. I will some day and, I promise ✋, I’ll do a post about that, to complete this one 😄
Decision logs
Same for the capability.
This decision logs feature should let you centralize any decision taken by the OPA engine (I should say engines). This can be absolutely required in a regulated environment for instance.
Same…. not tested yet. But I will let you know.
Monitoring
The OPA engine can expose a performance endpoint, to be used by a Prometheus db for instance.
Conclusions : my first impressions
I’m 100% convinced of the interest of this engine.
This engine brings the ability to follow the Cloud Native Application Principles of decoupling key components.
It is very efficient with a very low response time: no significant overhead to consider.
NOTE
I used this “demo set” at work with 2 friends. They were not entirely convinced, as they have in mind only the
allow= trueorallow=falseresult in mind, on a demo use case very, very simple (maybe too simplist?).I really need to identify another use case, to be able to mount another demo set (this time, including the audit and bundles), with result variable that aren’t just a
true/falsevalue, something with more added value (that could be more complex than just potentialif/then/else).However, I do no give up…. and that will be another post opportunity!
REGO language
It is a brand new language. As such, there is a learning curve.
I have to admit the language is not so complex, but to have a simple and efficient code may require more practice, for sure.
Unit tests
Most of the time, we will talk about authorization. As a consequence, the decision code absolutely needs to be strong, reliable and completely bug free.
Otherwise, the risk is to refuse an access to a legitimate call, or, worst, to allow an illegitimate one!
That is why strong unit tests seems absolutely required.
There a Styra blog entry about that.
Policy catalog
Thanks to bundles feature, it looks easy to centralize the policies, to have a policy bucket somewhere.
However, it also looks important to have the ability to identify them, to protect their access (to not spread authZ rules), and so on.
That may imply a kind of catalog tool, to keep track of all policies, access rights, version, usages across multiple OPA engines, etc…
I did not see anything like that in OPA world, but I may miss it.
The DAS
The OPA ecosystem is also compound of the Declarative Authorization Service (DAS).
I did not investigate on it for the moment. Stay tuned…
Deployment
Unfortunately, Kubernetes is not available everywhere, for everyone.
Then, the deployment process may be considered as a little bit more complex. Some smart solutions have to be imagined by avoiding the centralized pattern: having one instance of OPA Engine will automatically a high risk-single-point-of-failure…
Possible duplication
In some companies, a contract has been signed with well know authentication and authorization software companies. The “authorization” capability is then alreayd present in the IS ecosystem. ANd clearly, yes, OPA could be then considered as useless because duplicated system.
Nevertheless, keypoints in favor of OPA:
- decentralized
- open source
- easier management: application manager does not need to have some very restricted access to a centralized AuthZ server to adjust their own app policies
Last word
OPA community and interest is growing a lot: you can find more and more resources on internet.
One of them is a "curated list of awesome OPA related tools, framework and articles" on Github.
Enjoy!